
-
posts
-
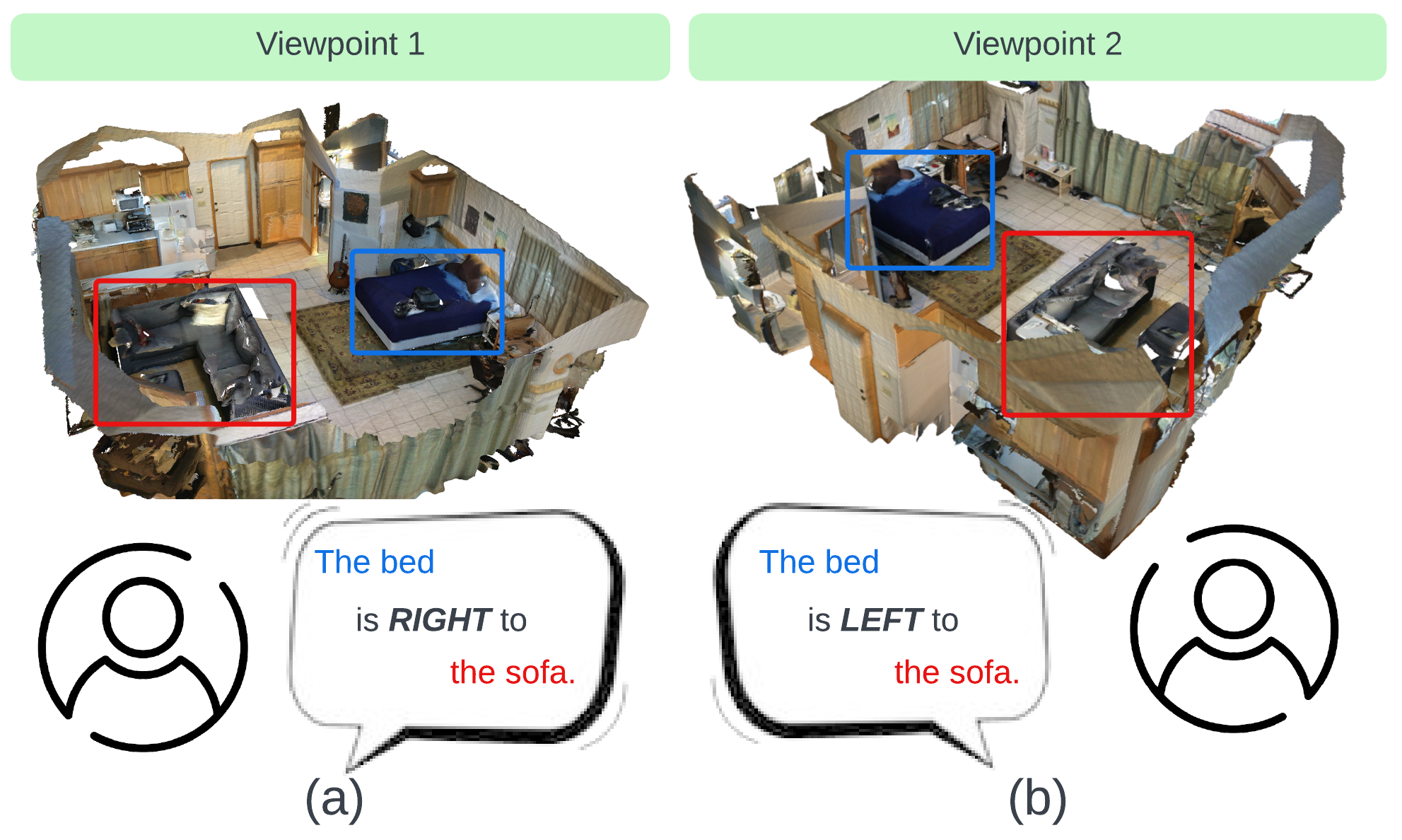
Viewpoint-Aware Visual Grounding in 3D Scenes
-
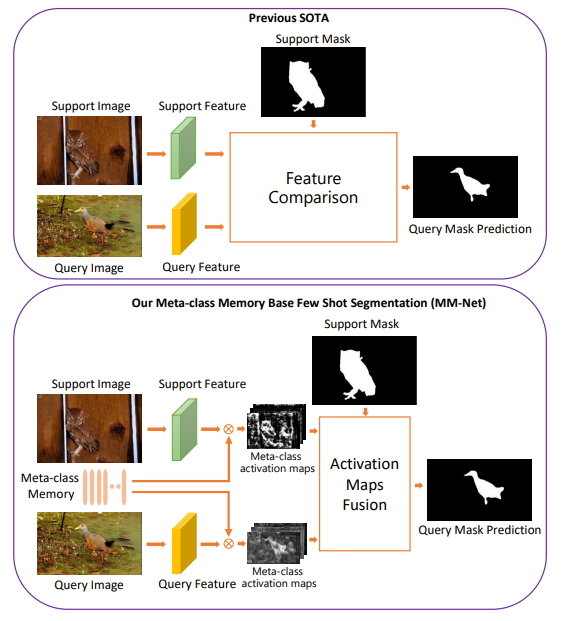
Learning Meta-class Memory for Few-Shot Semantic Segmentation
-
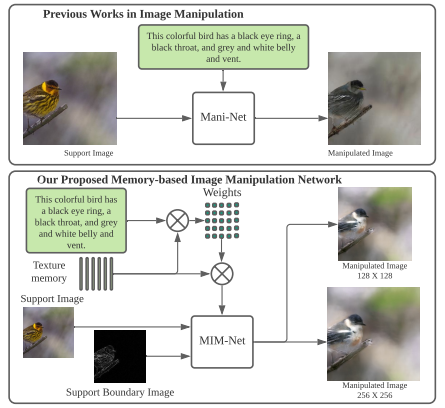
Remember What You have drawn: Semantic Image Manipulation with Memory
-
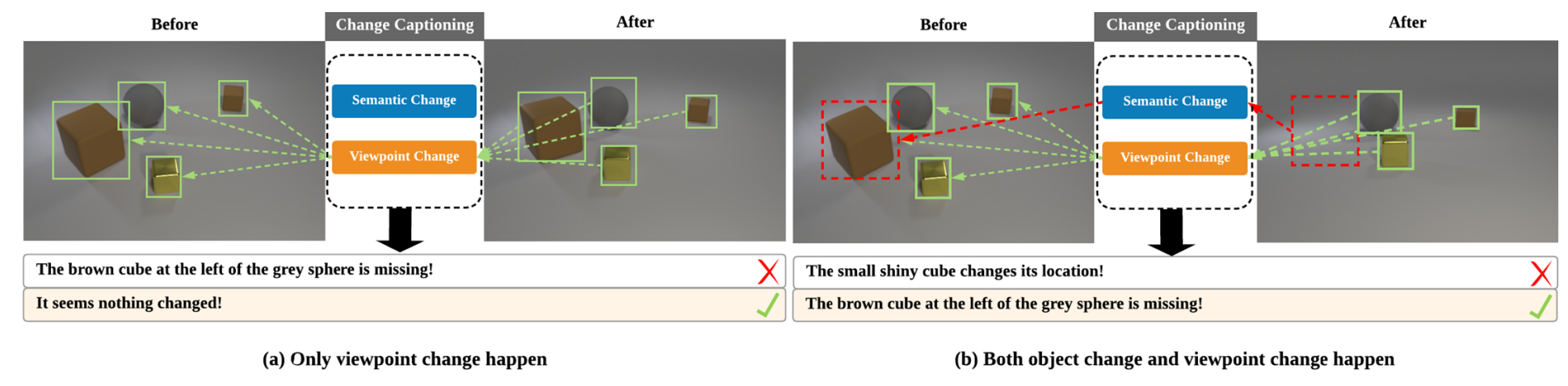
Finding it at another side: A viewpoint-adapted matching encoder for change captioning
-
Ask for Human Evaluation
Hi, everyone! Here a human evaluation is required for my current video captioning project. I would be grateful if you can spend some time on it to finish the evaluation. you can launch the system with http://155.69.146.170:5000. In the system, you need to evaluate a few samples, which requires watching a short video clip and evaluating 3 captions generated from the different models based on their relevance and richness. Thank you very much for your help.
-
Watch It Twice: Video Captioning with a Refocused Video Encoder
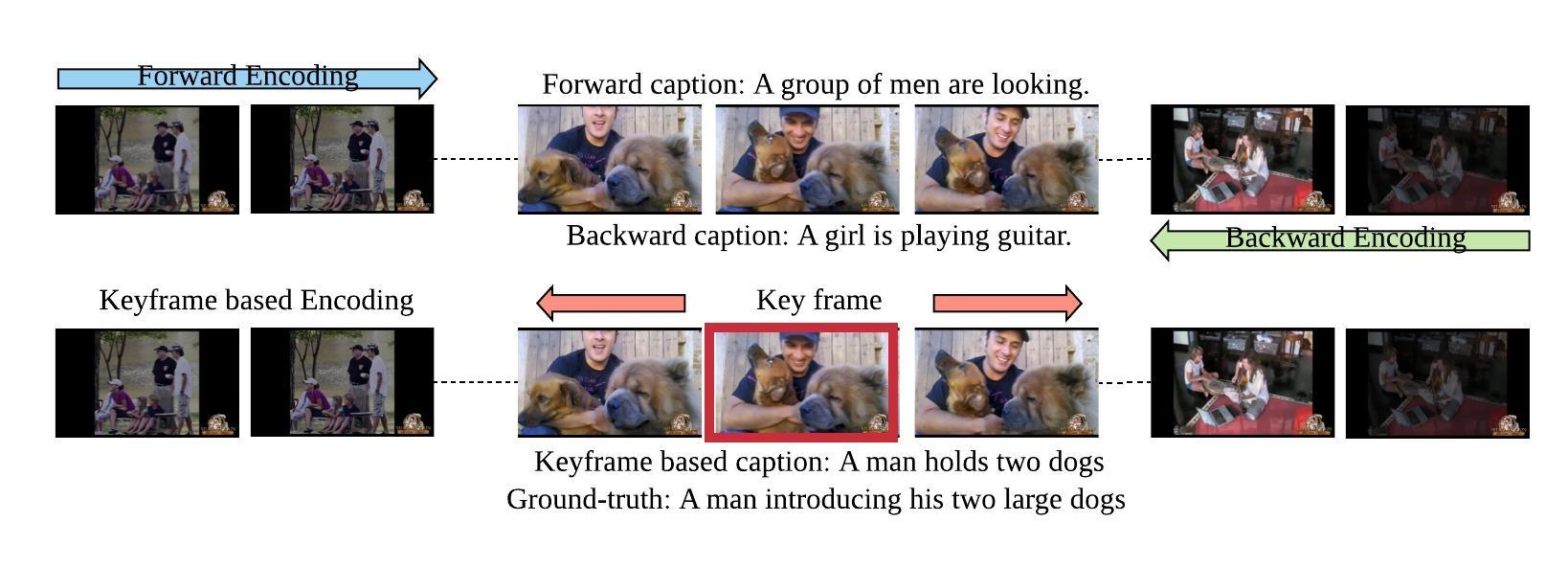
-
Video Captioning with Boundary-aware Hierarchical Language Decoding and Joint Video Prediction
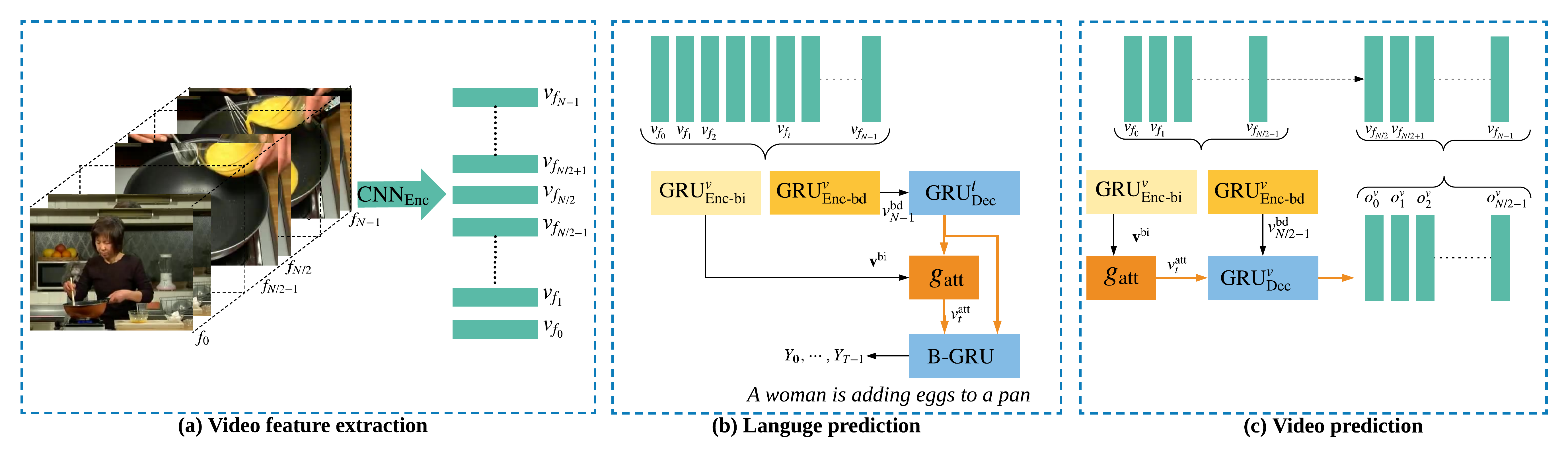
-
An iterative method for optical flow estimation with motion blur
VCIP, 2016
This paper presents a new method for estimating the optical flow of image sequences while considering the blur effect. In fact, the blur in input images can degrade the quality of optical flow, because it leads to ambiguities of pixel-match. Our method begins with an initial optical flow. Then two steps are performed iteratively until convergence, 1) the blur kernel is estimated using the information from optical flow; 2) the optical flow is estimated considering the blur kernel. Various experimental results verify the effectiveness of our method.
-
Hi! This is me.
Hi! My name is Xiangxi Shi. I am currently a PhD student in Oregon State University working with Dr. Stefan Lee's. I am interested in Out-of-Distribution Detection, Vision-Language Navigation, and 3D visual groudning.