
Xiangxi Shi Zhonghua Wu Stefan Lee
CVPR 2024
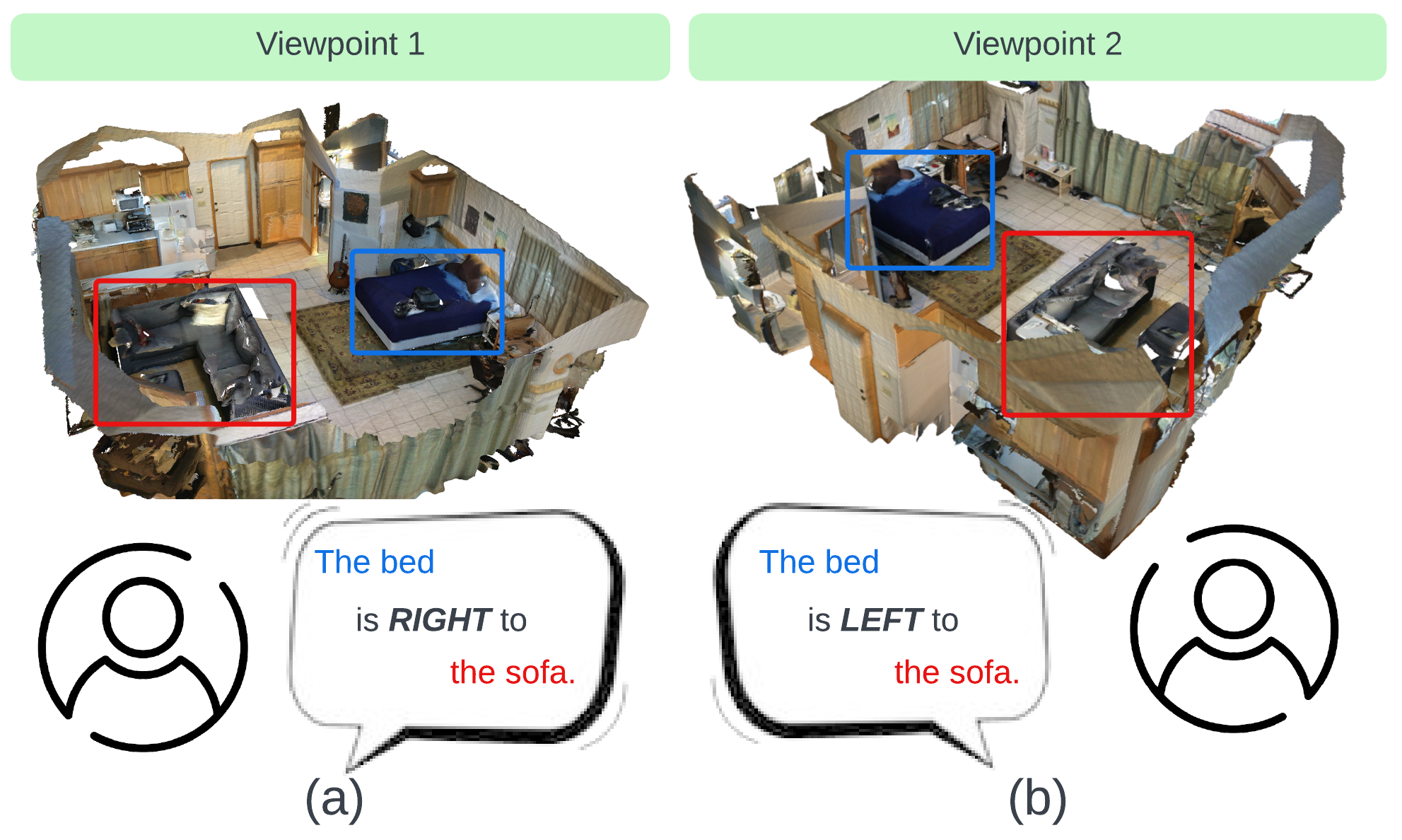
Referring expressions for visual objects often include descriptions of relative spatial arrangements to other objects -- e.g. ``to the right of'' -- that depend on the point of view of the speaker. In 2D referring expression tasks, this viewpoint is captured unambiguously in the image. However, grounding expressions with such spatial language in 3D without viewpoint annotations can be ambiguous. In this paper, we investigate the significance of viewpoint information in 3D visual grounding -- introducing a model that explicitly predicts the speaker's viewpoint based on the referring expression and scene. We pretrain this model on a synthetically generated dataset that provides viewpoint annotations and then finetune on 3D referring expression datasets. Further, we introduce an auxiliary uniform object representation loss to encourage viewpoint invariance in learned object representations. We find that our proposed ViewPoint Prediction Network (VPP-Net) achieves state-of-the-art performance on ScanRefer, SR3D, and NR3D -- improving Accuracy@0.25IoU by 1.06%, 0.60%, and 4.80% respectively compared to prior work.