
Xiangxi Shi Jianfei Cai Shafiq Joty Jiuxiang Gu
ACM-MM, 2019
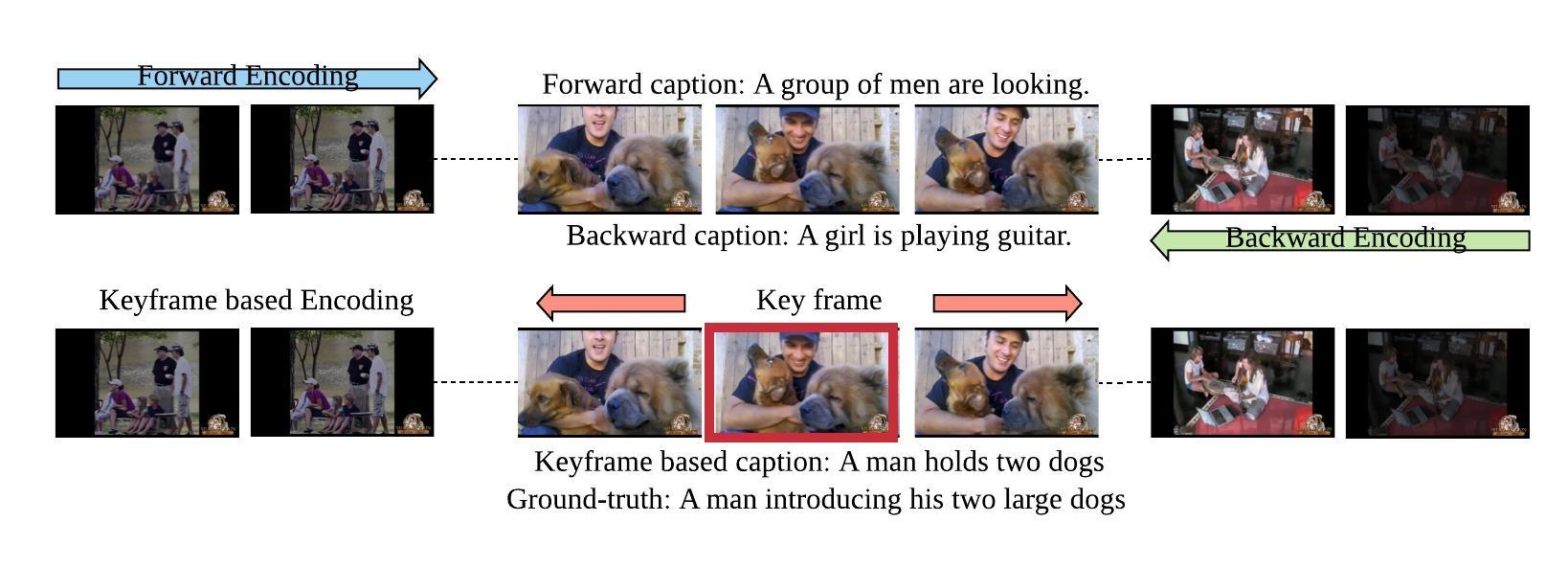
With the rapid growth of video data and the increasing demands of various crossmodal applications such as intelligent video search and assistance towards visually-impaired people, video captioning task has received a lot of attention recently in computer vision and natural language processing fields. The state-of-the-art video captioning methods focus more on encoding the temporal information, while lacking effective ways to remove irrelevant temporal information and also neglecting the spatial details. In particular, the current unidirectional video encoder can be negatively affected by irrelevant temporal information, especially the irrelevant information at the beginning and at the end of a video. In addition, disregarding detailed spatial features may lead to incorrect word choices in decoding. In this paper, we propose a novel recurrent video encoding method and a novel visual spatial feature for the video captioning task. The recurrent encoding module encodes the video twice with a predicted key frame to avoid irrelevant temporal information often occurring at the beginning and at the end of a video. The novel spatial features represent spatial information from different regions of a video and provide the decoder with more detailed information. Experiments on two benchmark datasets show superior performance of the proposed method.