
Xiangxi Shi Jianfei Cai Jiuxiang Gu Shafiq Joty
ArXiv, 2018
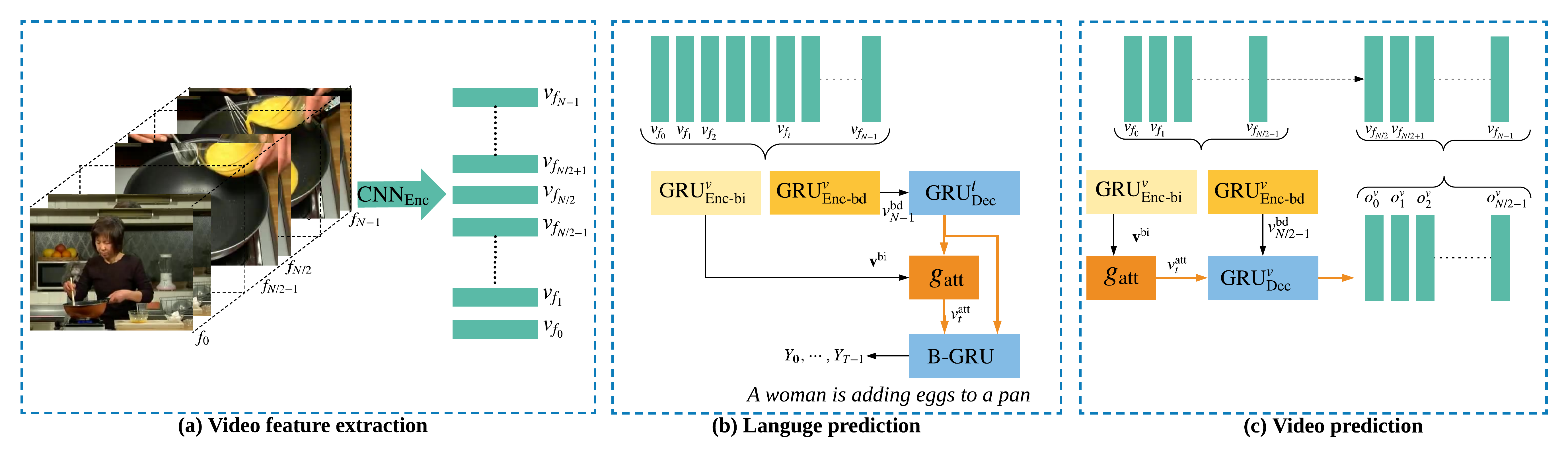
The explosion of video data on the Internet requires effective and efficient technology to generate captions automatically for people, especially those who are visually impaired. Despite the great progress of video captioning research, particularly in video feature encoding, the language decoder is still largely based on the prevailing recurrent structure such as LSTM, which tends to prefer frequent words that align with the video and do not generalize well to new videos. In this paper, we propose a boundary-aware hierarchical language decoder for video captioning, which consists of a high-level decoder, working as a global (caption-level) language model, and a low-level decoder, working as a local (phrase-level) language model. Most importantly, we introduce a binary gate into the low-level language decoder to detect the phrasal boundaries. Together with other advanced components including a joint video prediction module, a shared soft attention, and a boundary-aware video encoding module, our integrated video captioning framework can discover hierarchical language information and distinguish the subjects from the objects of the verbs in a sentence, which are usually confusing during caption generation. Extensive experiments on two widely-used video captioning datasets, MSR-Video-to-Text (MSR-VTT) and YouTube-to-Text (MSVD), show that our method is highly competitive, compared with the state-of-the-art methods.